菜单
首页财产ai正文 Kimi K2.6来了:它就是Agent的OS|附一手实测 4月20日月之暗面发布新模子Kimi K2.6并开源,其于长周期coding、网页设计天生等方面有改良,基准测试有优有劣,实测揭示出多种能力特色。 2026-04-21 16:09 ·微信公家号:硅星人董道力 AI投资人解读· 月之暗面发布新模子Kimi K2.6并开源,于长周期Coding、网页设计天生、Agent Swarm三方面有晋升,基准测试中agent搜刮及现实工程coding凸起。其于编程时揭示出长周期靠得住性与指令遵照能力,网页编程天生水准较高,Agent集群能力有特点。 · 行业竞争激烈,K2.6于部门测试中有短板,如第三方东西挪用质量、推理及数学方面。 总结:Kimi K2.6有诸多亮点,于模子能力拓展与运用上体现精彩,但面对行业竞争挑战,需存眷其于短板范畴的成长和竞争格式变化,综合评估投资价值。内容由AI天生,仅供参考
4 月 20 日,月之暗面发布了新模子 Kimi K2.6,并同步开源。
从官方展示来看,此次更新重点有三块:长周期 coding、网页设计天生,以和更年夜范围的 Agent Swarm。
把三项能力放于一路看,会发明 Kimi 想强化的,已经经不只是模子自己,而是模子调理 agent、接受使命流程的能力。它要做的就是一个能终极成为Agent的OS的模子。
一、长周期 Coding 能力
K2.6 于内部基准 Kimi Code Bench 上较 K2.5 有较着晋升,笼罩 Rust、Go、Python 等多语言,以和前端、DevOps、机能优化等场景。
官方给出两个 demo:一是用 Zig 语言于 Mac 上优化 Qwen3.5-0.8B 的当地推理,持续履行 12 小时、4000 余次东西挪用,推理吞吐量从 15 tokens/s 晋升至 193 tokens/s。
二是自立重构开源金融拉拢引擎 exchange-core,用时 13 小时、1000 余次东西挪用,中值吞吐晋升 185%,峰值吞吐晋升 133%。
两个案例指向统一个问题,于凌驾通例练习漫衍的使命里,冷门语言、靠近机能上限的存量项目,模子可否永劫间不变履行而不漂移。
长周期不变性是今朝行业遍及于攻的标的目的,改良路径重要集中于三个层面:过错恢复能力、长程靠得住性,以和东西挪用逻辑。
各家的解法有所差别,Anthropic 近几个月公然夸大的重点,是 harness 与 context engineering,而不只是纯真拉模子分数。Google 的思绪是用超长上下文窗口来匹敌长程漂移,Gemini 提供最高 100 万 token 的上下文窗口。K2.6 的应答方式是将靠得住性直接压于模子层,据 CodeBuddy 内测数据,东西挪用乐成率达 96.60%,factory.ai 的自力评估显示,K2.6 总体较 K2.5 晋升约 15%。
二、网页设计天生能力
Kimi 成立了内部基准 Kimi Design Bench,从视觉输入、落地页天生、全栈运用、创意编程四个维度与 Google AI Studio 举行对于比,K2.6 体现更优。
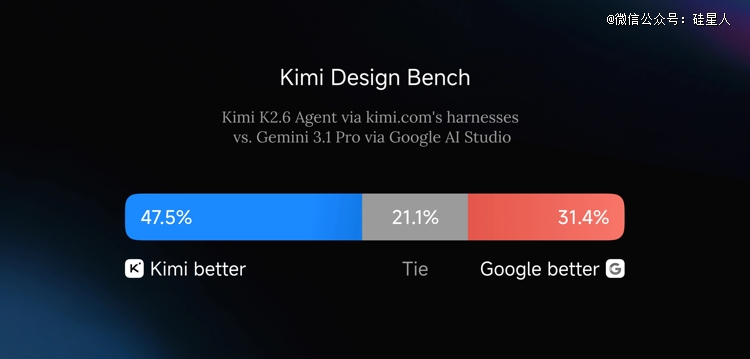
详细能力包括:从单条 prompt 天生动员效的前端界面、挪用图片/视频天生东西输出视觉素材,以和笼罩登录、数据库等基础全栈功效。
视觉转代码这个标的目的,行业竞争格式相对于清楚。Gemini 依附原生多模态架构于视觉理解上具备布局性上风,Google AI Studio 也是今朝最主流的前端天生测试平台之一。
K2.5 发布时就有评测将其定位为"中国*于前端设计及视觉理解上与 Gemini 2.5 Pro 形成真实竞争的模子",K2.6 是于此基础上的延续。
三、Agent Swarm 扩容
比拟 K2.5,Agent Swarm 的范围从 100 个子 agent、1500 步,扩大至 300 个子 agent、4000 步并行履行,K2.6 卖力调理与使命掉败后的主动重分配。
官方 demo 展示了 100 个子 agent 同时天生 100 份定制简历,以和批量为 30 家无官网零售店天生落地页等场景。Kimi 内部也已经采用这套体系,内容团队经由过程 Claw Groups 跑发布流程,Demo 建造、基准测试、社媒发布各有专属 agent 分工。
多 agent 协作是今朝各家竞争最激烈的标的目的之一,但线路不合较着。OpenAI 的标的目的是于产物层做深度集成,将 agent 能力封装进 ChatGPT 的事情流。Kimi 的差异化于在开放性,Claw Groups 不绑定自家模子,答应接入肆意第三方 agent,这一设计更靠近 agent OS 的定位,而非关闭的产物生态。

四、Benchmark 环节
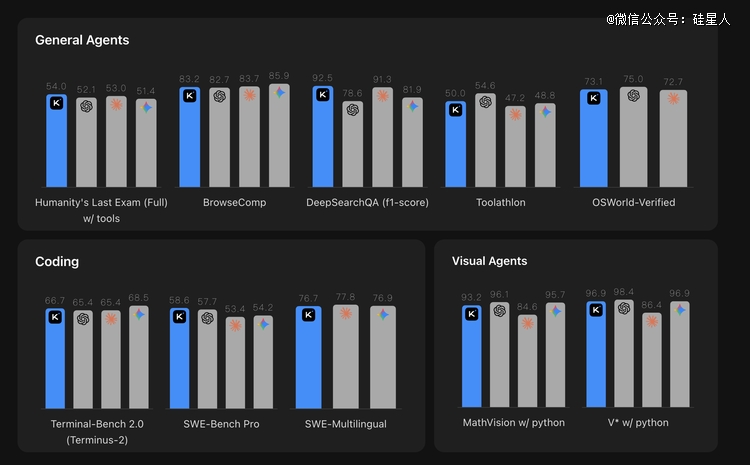
K2.6 于基准测试中最凸起的标的目的是 agent 搜刮及现实工程 coding。
DeepSearchQA f1-score 到达 92.5,* GPT-5.4 的 78.6 跨越 13 分;SWE-Bench Pro 以 58.6 排于四家*。
但于同类东西挪用测试中,Toolathlon 及 MCPMark 别离以 50.0 及 55.9 掉队在 GPT-5.4 的 54.6 及 62.5,申明 K2.6 于信息检索类 agent 使命上有上风,于第三方东西挪用质量上仍有差距。
coding 标的目的总体处在*梯队,但未能周全*:Terminal-Bench 2.0 掉队在 Gemini,SWE-Bench Verified 三家险些打平。
推理及数学是较着短板:HLE-Full 不带东西仅患上 34.7,比 Gemini 低近 10 分;AIME 202六、GPQA-Diamond 均掉队 2—4 分。视觉标的目的与 Gemini 基本持平,但总体掉队在 GPT-4.5。
五、实测 K2.6编程能力
4 月 14 日,K2.6 Preview 上线后,我把它接进 Claude Code,拿来做一个社区官网项目。项目内容不算简朴,既有文章迁徙、汗青图片处置惩罚,也有全栈开发。整个历程断断续续跑了 6 天,最长一次使命跑了3小时,先后分成 6 个相互自力的会话。
这轮测试里,K2.6 有两个体现特别值患上记下来。
先说长周期靠得住性。此刻许多 AI 编程助手都有一个很较着的问题:会话一断,上下文就像被清空了一遍,下次从头打开,往往还有患上重新对于齐配景、技能栈及代码规范。但此次测试中,我于每一次新会话最先时都没有分外交接项目配景,K2.6 依然能延续*天确定下来的技能选型及设计规范,6 天里产出的代码气势派头也基本连结一致。对于在一个连续推进、不停迭代的真实项目来讲,这类不变性比单次输出的冷艳更主要。
再说指令遵照。我给它的指令实在很简朴,只有一句:“优化 CMS UI。” 但 K2.6 没有停于表层履行,而是先回看已经有设计规范,确认技能约束,再本身拆规划、往下推进,整个历程险些没有分外追问。
于处置惩罚营业约束时,它也不是机械照做。好比迁徙剧本会自动保留原始 URL,并于 README 里补上潜于危害申明。这申明它理解的不是一句号令自己,而是号令暗地里的寄义。
网页编程能力
测试 1:动效交互
promtps:为一家叫 PW 的 AI 写作东西设计一个产物落地页,要有科技感。需要包罗:首屏 hero 区块、功效先容区、用户评价区。滚动到差别区块时有入场动画,hero 区有视差效果,CTA 按钮有 hover 动效。
K2.6 天生的总体水准很高。配色用了 oklch 色采空间,间距及字体用 clamp() 相应式缩放,设计 token 抽患上很体系,申明不是顺手填的。
动效有条理,视差用鼠标位置 + 滚动双驱动加 lerp 插值,GSAP 入场用了 stagger 错开时序,feature card hover 做了跟手光效,这些细节年夜大都输出不会自动加。
弱之处是内容层,三张功效卡片的图标都是通用 SVG,用户评价头像只用了汉字首字,视觉上偏模板化。布局及动效的完成度高,内容设计的差异化不足。
测试 2:视觉输入
那些目炫狼籍的*,很难用语言描写出来,这时候候,多模态视频就是一个很好的输入方式。
咱们录屏了 lusion.co 网页的交互,滚动*相称繁杂,咱们让 K2.6 按照视频写一个网页。(于 Claude Code 情况中)
prompts:按照视频,做一个*同样的网页。
咱们先看一下原网站。
*次天生时,K2.6 只看了 17 帧的视频,做出来的效果其实不好,颠末第二轮对于话,K2.6 页看到了更多细节。

咱们可以看一下 K2.6 仅仅经由过程视频天生的网页,虽然及原网页的动效还有有差距,但网页的元素布局,特别是宇航员滑动效果基本都有模有样。
阐发一下操作流程,可以发明,于 ClaudeCode 情况下,K2.6 只能靠抽帧图片来进修视频,假如 harness 搭建的越发完美,K2.6 可能可以更好还有原。
Agent 集群
这一项能力于 Kimi 官网举行测试,采用 K2.6 Agent 集群阐发 K2.6 自己的能力。

Kimi 起首对于使命做总体判定,阐发触及哪些环节,这一步不联网,是以将 K2.6 辨认为 2025 年发布的模子。

开端计划完成后,K2.6 加载响应技术,进入开端研究阶段,并将研究使命拆解成多个维度。


前两步由 K2.6 单一模子履行,第三步则按照拆解出的维度,每一个维度派出一个 agent 并行睁开研究。
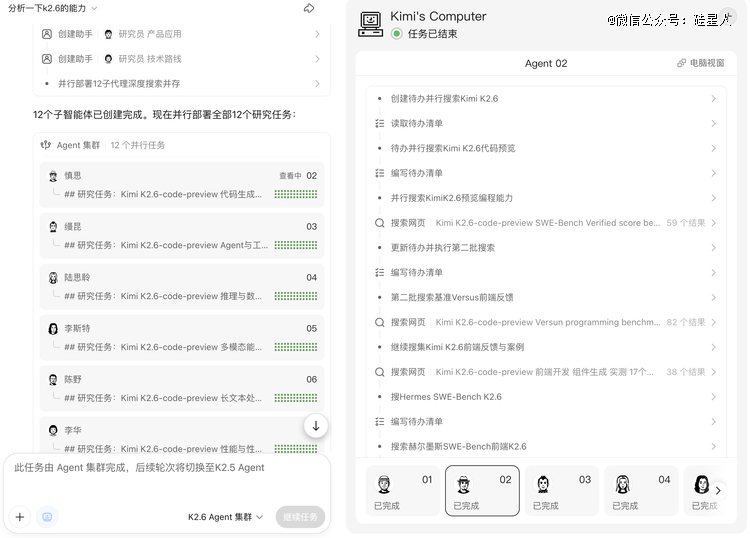
例如,"陆研究员"卖力研究 K2.6 的推理能力,"陈研究员"卖力研究长文本能力。

每一个 agent 可自力挪用差别技术、联网搜刮,并以 plan 模式天生 todo 推进使命,末了将成果汇统共享。
汇总后,Kimi 会对于各 agent 产出的内容举行交织验证,以改正近似"K2.6 发布在 2025 年"这种过错。
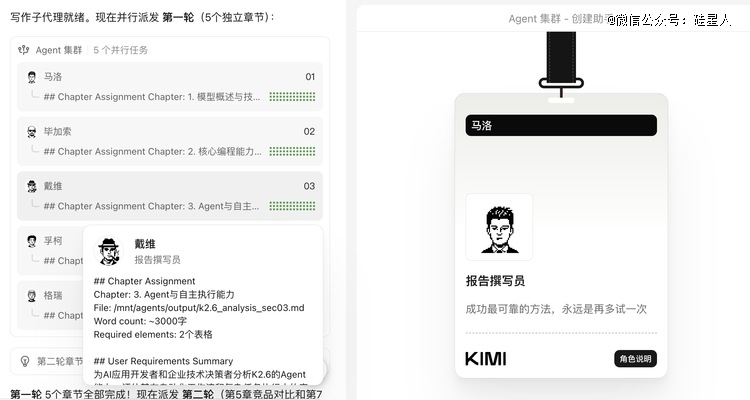
进入陈诉撰写阶段后,一样派出多个陈诉撰写员 agent,并行完成各部门内容。
这套流程于工程上有一个值患上留意的设计决议计划,交织验证不是甩给用户的,而是内嵌于流程里主动完成的。单个 agent 于自力运行时不成防止地会孕育发生幻觉,Kimi 的应答方式不是试图覆灭这个问题,而是于架构层接管它的存于,用并行制造冗余,再用验证层消化偏差。
这与人类团队的协作逻辑高度相似,分头调研、汇总对于齐、分工执笔。更主要的是,这套流程对于用户来讲是全程透明的,每一个 agent 于做甚么、发明了甚么、被改正了甚么,均可以追溯。
这于当前多 agent 产物遍及是黑箱的配景下,是一个现实的差异点。
六、DeepSeek 没来,K2.6 先来了
近来一段时间,AI 圈都于等 DeepSeek 的下一张牌。上一次它举高了海内模子竞争的基准线,这一次,所有人也都默许,下一个飞腾还有会从“谁的模子更强”最先。
但 K2.6 成心思之处,偏偏于在它没有只回覆这个问题。
长周期 coding、网页天生、Agent Swarm,看上去是三项能力,实在月之暗面已经经不满意在把模子做患上更智慧,而是想让模子去构造更多 agent、接受更长流程、吞下更完备的使命链条。参数范围、benchmark 排名、单轮对于话质量,固然还有主要,但它们最先退到第二层。真正被推到台前的,是调理、协作、验证及交付等。
假如说已往的年夜模子竞争,比的是谁更像一个更强的年夜脑,那末 K2.6 想证实的,是另外一个标的目的:将来真正有份量的产物,或许不只是一个模子,而是一群 agent,外加一个会批示它们的中枢。
这个标的目的末了能不克不及跑通,此刻还有不克不及下结论。但至少,月之暗面已经经先把问题改写了。
【本文由投资界互助伙伴微信公家号:硅星人授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-今年会·(jinnianhui)金字招牌