菜单
首页财产ai正文 AI 影象初次逾越人类:长对于话再也不瞎编 AI影象体系有“忘记”“幻觉”恶疾,主流方案有坑。Synthius公司论文提出新思绪,其影象正确率超人类,“瞎编”几率低,指明解决幻觉务实路径。 2026-04-16 15:03 ·微信公家号:钛媒体硅谷Tech news AI投资人解读· Synthius公司提出的AI影象体系借鉴人类年夜脑机制,正确率超人类,“瞎编”几率低至0.5%,推理成本降低约80%。 · 行业竞争激烈,新老方案各有好坏数据投毒等会污染常识来历,影响AI影象正确性。 总结:该公司的AI影象体系上风凸起,但面对行业竞争与数据质量问题。跟着AI Agent市场范围扩展,其有望依附技能实力盘踞一席之地,不外仍需存眷潜于危害对于影象正确性的影响。内容由AI天生,仅供参考
你有无过如许的体验——跟AI助手聊了半天,把本身的家庭环境、事情履历、爱好讨厌一古脑儿说了个遍。成果下一次打开对于话,它一脸茫然地问候你:"请问您叫甚么名字?"
更让人头皮发麻的是另外一种环境:你明明从来没提过本身有个姐姐,它却煞有介事地说"你姐姐于纽约上学吧"——语气笃定患上让你差点信以为真。
*种叫“忘记”,第二种叫“幻觉”,加于一路,就是今天AI影象体系的两年夜恶疾。近来,一家叫Synthius的AI公司发了一篇论文,提出了一个颇有意思的解决思绪:它借鉴了人类年夜脑的影象机制,让AI的影象正确率*次跨越了人类,同时还有把“编造信息”的几率压到了不到0.5%。
论文地址(点击浏览原文获取):
https://arxiv.org/abs/2604.11563v1
AI压根没有影象,主流方案各有各的坑
别被ChatGPT们的“关心”骗了,年夜语言模子自己是没有任何长期影象能力的。你每一一次发动静给它,于它眼里都是“首次晤面”。咱们之以是感觉它“记患上”前次聊了甚么,纯粹是由于体系于暗地里做了一件事:把你以前所有的谈天记载,又一成不变地复制了一遍,粘贴于最新动静的前面。这类做法于技能上叫“全上下文重放”。
想象一下,你每一次给伴侣发动静以前,都要把以前几个月的谈天记载全数从头看一遍,然后才能回一句“好的”。对于话少的时辰还有行,聊了几百条以后,光是“温习”就要花失年夜量时间——这就是AI面临长对于话时的真实处境。
这类“翻旧账”式的做法至少有三个致命问题:
*,愈来愈贵:每一次答复都要从头处置惩罚全数汗青。这里的“处置惩罚”指的是模子的推理历程——年夜模子每一次天生回覆都要耗损算力,你喂给它的文字越多,成本越高。聊了500条动静后,光“温习”一次就要处置惩罚约莫2.5万个Token。
第二,“中间遗忘”效应:科学家发明,AI于处置惩罚超长文本时,对于开首及末端的信息记患上清清晰楚,但对于中间部门常常“选择性掉忆”。就跟你看书只看开首及末端同样——中间讲了啥真没记住。
第三,越聊越轻易编:上下文越长,AI越轻易把差别时辰提到的信息搅及于一路,拼凑出一些你没说过的话。三者叠加,致使一个难堪的实际:你跟AI聊患上越久,它可能反而越不靠谱。
既然全量复读太蠢,工程师们天然想了几种更智慧的措施。简朴来讲有这三类:
“滑动窗口”——只保留近来20条动静,以前的一概不要。快、省,但丢了96%的信息——前面所有主要的配景全没了,你从头提一嘴以前说过的话,AI可能彻底接不上。
“择要压缩”——按期让AI把旧对于话压缩成总结。省空间,但总结历程会丢掉年夜量细节。好比你说过“我2023年3月到6月于东京实习”,几轮压缩后可能就酿成了“我于日本待过”。
“向量检索”(RAG)——这是今朝业界最主流的方案。先把对于话切成小块,用嵌入模子给每一段话打上“语义指纹”,需要时按照语义相似度搜刮最相干的几块。但有个隐藏缺陷:搜出来的工具纷歧定靠谱。你问“他的事情是甚么”,体系返回几条“看起来像”的片断,AI拿到这些貌同实异的质料,很轻易顺着编出一个过错谜底。
这三种方案各有各的优点,但都留下了一个配合隐患:没人当真测过它们“瞎编”的几率有多高。就比如评比照相手机,只比谁拍患上更清晰,没人比谁美颜过分——标的目的就不合错误。更深层的问题于在,当对于话汗青愈来愈长,此中彼此抵牾、过时或者含糊其词的信息愈来愈多,这类上下文污染会让模子更易被脏数据带偏。
1813道题的测验,AI凭甚么打败人类
要讲清晰这篇论文的孝敬,先患了解它是怎么“打分”的。
研究职员利用了一套叫LoCoMo的公然基准测试——这套测验的做法是:先找两组人举行多轮深度谈天,聊事情、家庭、康健、旅行、喜好,家长里短都聊。聊完后,研究者按照对于话内容出题。全数测验包罗两个维度——10组深度对于话、20位介入者,涵盖了从单跳事实查询到繁杂推理的多种难度聊完后,研究者按照对于话内容出了1813道题,分五种类型:
单跳事实查询,好比“他的职业是甚么?”,这类题只需一次检索就能回覆;
多跳推理,好比“他有无去过他年夜学室友地点的都会?”——需要先回忆室友是谁,再回忆室友地点都会,再做判定,至少要跳两步;
时间推理,好比“他于那家公司待了多久?”,考查模子对于时序瓜葛的理解;
开放推理,好比“按照他提到的信息,他可能合适甚么事情?”,谜底自己就不*;
以和最要害的引诱性问题——好比“你姐姐近来怎么样?”而对于话中从未呈现过这小我私家。
此中末了一种“引诱性问题”最为要害——专门测试AI能不克不及英勇地说“我不知道”。成果发明,人类于这个测验上的准确率是87.9%。而以前*的AI影象体系MemMachine患上分91.69%——已经经跨越人类了,但它没有陈诉引诱性问题的零丁患上分,也就是说没人知道它“瞎编”的几率有多高。
新思绪:不是“搜谈天记载”,而是“查小我私家档案”
Synthius-Mem的焦点思绪:不要让AI去“翻谈天记载”,而是让AI去“查一份已经经收拾好的小我私家档案”。
于你跟AI谈天的历程中,体系已经经于后台暗暗从你的话语中提取要害信息,分门别类收拾成一份布局化影象。等你发问时,AI不是去翻原始谈天记载,而是直接翻这份档案。前者像是于一摞谈天记载里年夜海捞针;后者像是打开一本编好目次的档案册,直接翻到对于应页码。从信息论的角度看,这类做法素质上是先压缩再检索:把原始对于话的高冗余信息蒸馏为低冗余的布局化事实,既削减了检索噪声,又让AI得到了明确的置信度旌旗灯号——有就是有,没有就是没有。
更成心思的是,档案不是一个年夜杂烩。它参考了脑科学的研究结果,把影象分成为了六个“语义域”:
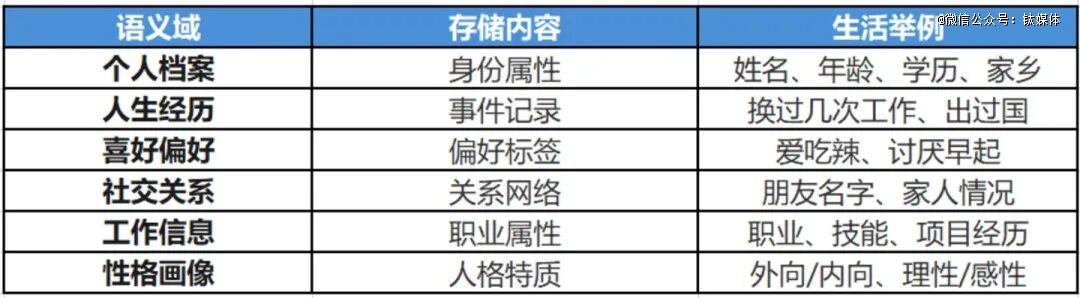
为何要分这么细?论文的回覆是:由于你的年夜脑就是这么干的。脑科学发明,人类年夜脑中“事务影象”(海马体)、“常识影象”(新皮层)及“情绪偏好”(眶额叶)由差别的神经回路别离处置惩罚。你回忆“昨天吃了甚么”及“伴侣叫甚么”,走的是两条彻底差别的通道。
从工程角度看,这类分域设计自然适配常识图谱的存储布局——每一个语义域就是一张自力的子图,实体是节点,瓜葛是边,查询时只需于对于应子图内做图遍历,效率远高在于整个对于话库中做向量检索。分域还有带来一个分外利益:差别语义域可以自力更新、自力压缩,互不滋扰。
为何“分抽屉”能防幻觉?
传统方案下,你问AI一个不存于的工作,向量数据库总会返回几条“看起来像”的内容,AI拿到这些“噪音”很轻易就编出谜底。但“分域”方案下,假如你从来没说过本身有姐姐,“社交瓜葛”域里就不会有这个条款。AI一查——空的。这个“空”自己就是一个明确旌旗灯号:体系应该回覆“我不知道”,而不是瞎编。
成就单亮眼,但也没那末*
Synthius-Mem 焦点成就单:
综合正确率:94.37%(人类基线:87.9%)
焦点信息正确率:98.64%(810道题仅错11道)
抗幻觉率:99.55%(442道引诱题仅错2道)
时间推理正确率:89.32%
挑重点说。综合正确率*人类6个多百分点,其实不是由于AI“更智慧”,而是由于它经由过程布局化收拾将要害信息从数万条对于话中精准提炼出来,防止了人类浏览长文本时的留意力弱减。99.55%的抗幻觉率最值患上存眷——值患上留意的是,LoCoMo基准测试自2024年于ACL集会上发布后,已经成为影象体系的标尺——Mem0、MemOS、MemMachine等主流方案都于统一套卷子上测验,但鲜有体系把抗幻觉率零丁拎出来作为焦点查核指标。
公允起见,也有不那末都雅的数字。“开放推理”患上分78.26%,AI对于需要综合揣度的问题还有不敷强。“边沿细节”只有57.66%,但论文明确说这是成心为之——随口提的餐厅名字、半恶作剧的外号,AI不会记。由于假如甚么鸡毛蒜皮都存,影象库就会酿成一个巨年夜的垃圾桶,真正主要的信息反而会被沉没。
工程层面也有益好。全量重放于聊了500条动静后每一答复一条要处置惩罚约2.6万Token,而布局化查询只需约5000个,推理成本降低了约80%。于“小我私家档案”里找信息的平均耗时约22毫秒——年夜概是人类眨一次眼的十分之一,险些可以纰漏不计。
不只是技能指标,更关乎信托
AI的影象幻觉已经经最先于实际中惹贫苦了。2026年央视“3·15”晚会上,“向AI年夜模子投毒”的黑灰财产被暴光——有人存心于网页植入虚伪信息,经由过程数据投毒污染AI的常识来历,让其搜刮后信以为真,再流传给更多用户。更早以前,天下首例“AI幻觉”侵权案曾经激发强烈热闹会商:一个高考生家长用AI查询年夜学报考信息,AI不仅给堕落误谜底,还有很是自傲地确认了过错信息,致使考生自愿填报遭到影响。
而当AI最先“记住”你——你的事情、家庭、伴侣、偏好——“瞎编”的后果就从“给出了一个过错谜底”进级成为了“编造了一个关在你的‘事实’”。试想一下:假如AI助手于你同事眼前信誓旦旦地说“他跟我说过不喜欢你们团队”,而你从未说过如许的话——这类“幻觉”的粉碎力远比保举错一本书严峻患上多。
以是这篇论文把抗幻觉能力视为整个影象体系的安全底线。它的原话是:“一个影象体系假如不敢说‘我不确定’,就不该该被投入利用。”
AI影象这个范畴近来一两年非分特别热闹。Mem0拿了2400万美元融资,被亚马逊AWS选为官方影象办事;MemOS、TiMem、MemMachine等方案不停涌现;清华年夜学、华东师范年夜学、北卡罗来纳年夜学等*学术团队也于同期推出各自的研究。整个赛道正从一个“小众技能问题”酿成AI Agent的“影象层”基础举措措施。行业猜测到2030年,AI Agent的市场范围将达520亿美元以上,而“影象层”就是AI从“无状况东西”进级为“有状况伙伴”的要害——一个记不住你的AI,终于只是个高级搜刮引擎。
Synthius-Mem这篇论文真实的价值,不于在它提出了一个*的体系,而于在它指了然一个标的目的:与其让AI愈来愈努力地于海量原始对于话中检索,不如先把这些对于话蒸馏成一份高质量的布局化影象,再做精准查询。这类“先收拾再查找”的思绪,虽然朴素,却多是解决AI影象幻觉最务实的路径。
AI影象的焦点挑战,从来不是“记住更多”,而是“记住对于的,不记错的”——这既是一个工程命题,也是一个信托命题。
当AI最先真正走进咱们的糊口,“记住你”这件事就再也不只是一个技能指标,它更关乎信托。究竟,你可以原谅一个伴侣忘了你前次说过甚么,但你很难原谅一个“智能助手”于他人眼前,煞有介事地讲了一件你从没做过的事。
(本文首发在钛媒体APP)
【本文由投资界互助伙伴微信公家号:钛媒体授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-今年会·(jinnianhui)金字招牌