菜单
首页财产ai正文 DeepSeek 正式发布 V4,API:Flash/Pro 双版本齐发 五一前两日年夜模子进入发布潮,DeepSeek V4发布,标配1M超长上下文,开源模子权重及技能陈诉,于能力、成本、开源等方面有冲破。 2026-04-24 14:52 ·微信公家号:极客公园连冉 AI投资人解读· DeepSeek V4发布,V4-Pro及V4-Flash全系标配1M超长上下文,同步开源模子权重及技能陈诉,年夜幅降低长文本处置惩罚门坎。Flash版本主打极致低延迟与高性价比,Pro版天性能强劲,官方订价低在海外同级别旗舰闭源模子。 · 行业竞争激烈,模子更新换代快,需连续存眷技能成长与市场变化。 总结:DeepSeek V4依附技能立异与开源计谋揭示强盛竞争力,为开发者提供高性价比选择,具备较年夜投资潜力,但要注意竞争加重危害。内容由AI天生,仅供参考
万众期待中,DeepSeek V4,终究发布了!
就于方才,被期待已经久的 DeepSeek V4 预览版正式登场。两个版本——V4-Pro 及 V4-Flash,全系标配 1M(百万字)超长上下文,同步开源模子权重及技能陈诉。
五一前的这两天,年夜模子又进入新一轮发布潮。
4 月 23 日午时,「天才少年」姚顺雨交出插手腾讯后的*份模子答卷,腾讯混元 Hy3 预览版表态,2950 亿参数的 MoE 架构,激活参数 21B,推理效率晋升 40%,输入价格压到 1.2 元/百万 tokens。
今天凌晨,OpenAI 面向付用度户上线 GPT-5.5 并官宣 API 规划,主打 Agent 事情流及多步调使命完成,上下文窗口拉到 100 万 tokens,API 订价也水长船高——输入 5 美元、输出 30 美元/百万 tokens。
外貌上,三家路径各不不异:OpenAI 走高端闭源线路,继承举高价格天花板;腾讯把模子塞进自家生态,用性价比撬动范围化商用;DeepSeek 则延续开源传统,同时把上下文长度推到一个新的普光临界点。
同时,Agent 能力、超长上下文、代码与东西挪用,这三个要害词,于三家发布的新模子里重复呈现。他们都于统一个标的目的上加注:让模子能处置惩罚更长的信息,能于更繁杂的使命链条里自立运作,能真正嵌入到事情流程中去「干活」。
0一、DeepSeek V4 的「实用主义」
DeepSeek 此次发布,把百万字上下文从「高端选配」酿成了「基础标配」。
于此以前,1M 级另外上下文长度,更多呈现于旗舰闭源模子的高端版本里,昂扬的挪用成本足,以让年夜大都开发者及中小企业望而生畏。
而 DeepSeek 的做法十分明确:V4-Pro 及 V4-Flash 两个版本全系标配 1M 上下文长度,前者锚定*机能,后者提供普惠经济之选,完备笼罩差别需求层级的用户。这类「无不同下放焦点能力」的计谋,素质上是于完全降低长文本处置惩罚能力的行业获取门坎。

图片来历:DeepSeek 官网
Flash 版本主打*低延迟与高性价比,是 DeepSeek 面向轻量化高频场景给出的焦点方案。依附 13B 的激活参数、全新的 token 压缩留意力机制与 DSA 稀少留意力架构优化,它于保障靠近 Pro 版焦点推理能力的同时,实现了极快的相应速率,对于在及时对于话交互、函数挪用流水线,以致所有对于相应速率敏感的轻量化场景而言,这一特征能带来体验上的素质晋升。
更要害的是具备竞争力的成本布局。
按照 DeepSeek 官方 API 订价文档,Flash 版本采用阶梯式计费法则:缓存掷中的输入 token 低至 0.2 元 / 百万 tokens,缓存未掷中的输入 token 为 1 元 / 百万 tokens,输出 token 订价为 2 元 / 百万 tokens。
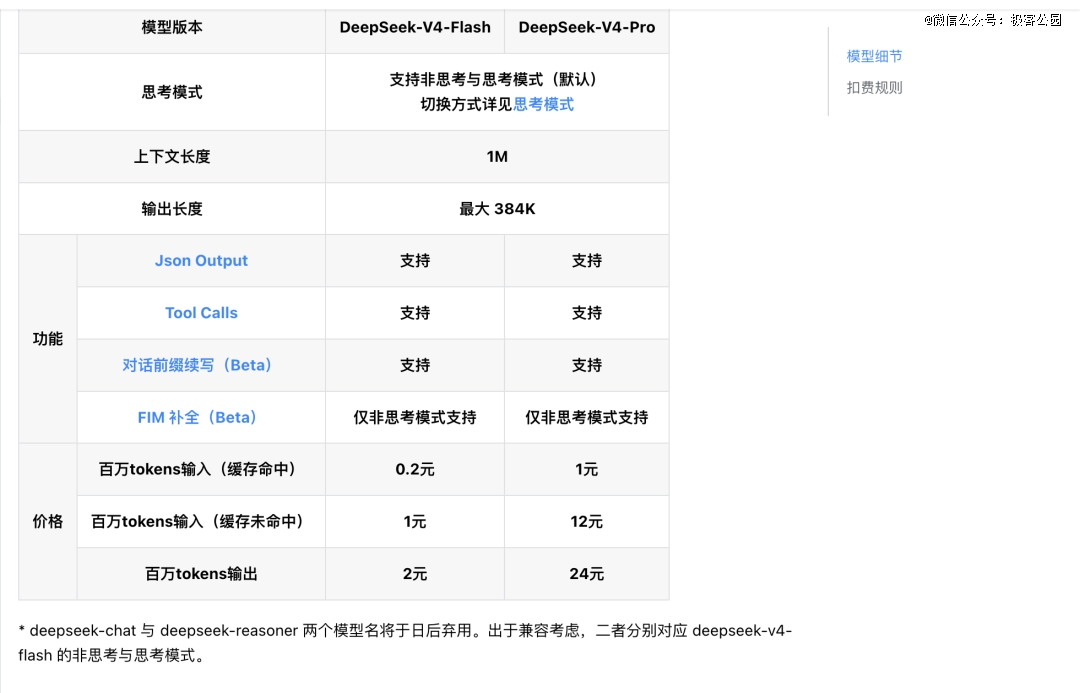
DeepSeek V4 各个版本成为|图片来历:DeepSeek API 文档
云云亲平易近的订价,叠加全系标配的 1M 上下文能力,使患上「单次挪用成本」再也不是工程设计中的焦点约束——开发者可以优先思量产物体验与架构设计,而无需重复于挪用次数与用度之间做衡量。
Flash 解决的是「用患上起、用患上快」的普惠需求,V4-Pro 则于回覆另外一个焦点问题:开源年夜模子的能力界限,毕竟还有能被推到哪里。
最直不雅的能力跃升,依然缭绕长上下文睁开。DeepSeek 将模子上下文长度从上一代 V3.2 的 128K,直接拉升至 1M(一百万 token),共同底层架构的立异,于年夜幅降低长上下文计较与显存需求的同时,保障了全上下文窗口的机能无损。
于这一范围下,开发者可以直接导入完备代码库、超长行业文档、多轮项目档案甚至百万字级另外完备册本举行端到端处置惩罚,无需分外搭建繁杂的检索加强天生(RAG)体系,年夜幅简化了长文本处置惩罚的技能链路。
于底层架构上,Pro 版本采用了总参数 1.6T、激活参数 49B 的 MoE 架构,预练习数据量达 33T,是对于 DeepSeek 混淆专家线路的周全深化。官方评测数据显示,其于数学、STEM、竞赛级代码等焦点推理测评中,逾越了当前所有已经公然评测的开源模子,到达了比肩世界*闭源模子的程度。
于 Agent 能力上,其交付质量已经靠近 Claude Opus 4.6 非思索模式,内部利用反馈优在 Anthropic Sonnet 4.5,成了 DeepSeek 内部员工的主力 Agentic Coding 东西。
功效层面,V4 全系列两个版本均同时撑持非思索模式与思索模式,开发者可经由过程 reasoning_effort 参数自界说思索强度,同时全量撑持 Json Output、Tool Calls、对于话前缀续写能力。
订价方面,Pro 版本一样延续了高性价比线路,官方订价为:缓存掷中的输入 token1 元 / 百万 tokens,缓存未掷中的输入 token12 元 / 百万 tokens,输出 token 订价 24 元 / 百万 tokens,显著低在海外同级别旗舰闭源模子。
API 接入也做到了*低门坎,开发者无需修改原有 base_url,仅需将 model 参数替代为对于应版本名称,便可完成接入,同时兼容 OpenAI ChatCompletions 与 Anthropic 两种接口格局。
这类「能力上探 + 成本下探」的组合拳,让*的年夜模子能力再也不是少数厂商的专属资源。当行业内卷逐渐堕入参数武备竞赛的怪圈,DeepSeek 用全系标配百万上下文、全链路开源开放的选择,给年夜模子的普惠化,给出了一个全新的范本。
同时,DeepSeek V4 针对于 Claude Code、OpenClaw、OpenCode、CodeBuddy 等主流 Agent 产物做了专项适配及优化,于代码使命、文档天生等现实场景中体现均有晋升。模子的价值终极要于真正的开发及事情流程里被查验。
0二、继承开源,API 全量开放
DeepSeek 延续了开源线路,并直接全量开放 API 挪用。
今朝,DeepSeek-V4 的模子权重已经同步于 Hugging Face、ModelScope 平台开放下载,配套的技能陈诉也一并公然,撑持开发者举行当地部署与二次开发。
与部门厂商「开源阉割版、闭源完备版」的行业惯例差别,本次开源的两个版本,完备保留了与官方云端 API 一致的全量能力——包括非思索 / 思索双模式、1M 超长上下文无损处置惩罚、Agent 专项优化与全量东西挪用能力,无任何功效阉割。
这象征着,不管是中小创业公司、小我私家开发者,还有是科研机构,都能零门坎获取到百万上下文、*推理与 Agent 能力的年夜模子底座,无需再为高端模子能力付出高额的闭源接口用度。
为了进一步降低沉地门坎,DeepSeek 同步开源了模子微调、量化、推理加快的全流程东西链,完成为了 vLLM、TGI 等主流推理框架,以和 LangChain、LlamaIndex 等主流 Agent 框架的 Day 0 原生适配,同时开放了国产算力平台的全栈部署方案,闪开发者于差别硬件情况下都能快速落地运用。
与此同时,DeepSeek 也给出了清楚的模子迭代过渡方案:旧有的 API 接口模子名 deepseek-chat 与 deepseek-reasoner,将在三个月后(2026 年 7 月 24 日)住手利用,当前阶段,这两个模子名别离指向 deepseek-v4-flash 的非思索模式与思索模式,给开发者留出了足够的光滑迁徙时间。
0三、坚定做 AI「基建模子」
把这两天的发布连起来看,一个趋向很明确:各家都于加快 Agent 能力。
已往两年,公家及本钱市场对于年夜模子的存眷,很年夜水平上集中于「智慧水平」,但此刻已经经转向了「谁更能不变地把工作做完」。GPT-5.5 的发布重点不于在多模态理解又晋升了几多,而是它于 Agent 编程、计较机利用、常识事情等场景中的连续履行能力。腾讯混元 Hy3 的焦点卖点也于在它于实际世界中的「步履能力」。DeepSeek V4 则直接把 Agent 能力及长上下文处置惩罚作为主打,方针明确地指向现实事情负载。
这类改变的暗地里,是整个行业正于走向「模子效用」的竞争。此刻,用户及企业客户愈来愈不体贴你的模子于某项评测里排第几,他们体贴的是模子和产物到底能帮本身干很多多少少活儿:这个模子能不克不及帮我写代码、能不克不及处置惩罚繁杂文档、能不克不及于多步调使命里不堕落、能不克不及以合理的成本跑起来。

图片来历:DeepSeek 官网
于今天发布的文末,DeepSeek 援用了《荀子》里的一句话:「不诱在誉,不恐在诽,率道而行,端然正己」,继承锚定了本身的技能线路。放于当下的年夜模子竞争语境下,这句话的象征很明确——不被外界的评价及噪音滋扰,专注在把工作做对于。
DeepSeek 已往一年多的步履,确凿于践行这个逻辑:用开源开放成立全世界开发者生态影响力,用*的性价比打破高端 AI 能力的利用壁垒,用扎实的底层架构立异解决开发者与企业用户最真正的痛点。
从 R1 推理模子的横空出生避世,到 V4 把长上下文能力*次推向普惠区间,DeepSeek 一直于用一种相对于「慢」的方式,做一件更难的事——把*模子能力,从少数人的东西,酿成更多人可以直接挪用的基础举措措施。
【本文由投资界互助伙伴微信公家号:极客公园授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-今年会·(jinnianhui)金字招牌